Inception V2/3 : Rethinking the Inception Architecture for Computer Vision (2015.12.)
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna
https://arxiv.org/abs/1512.00567
오늘 리뷰할 논문은 Inception 모듈 버전 2,3에 대한 내용을 중점적으로 다루고 있는 2015년에 발표된 Rethinking the Inception Architecture for Computer Vision입니다. 논문 리뷰 시작하겠습니다
📌 Abstract
Convolution Network의 layer를 깊게 쌓는 방법론을 적용함에 있어서 CNN 분야에서 큰 성능 개선을 이루었지만,
모델 크기의 확장을 통한 성능 개선에는 막대한 계산량이라는 한계가 항상 따라왔습니다.
하지만, 여러 Vision Task들을 적용함에 있어서 적은 파라미터와 그에 따른 계산 효율성은 필수적인 요소이며,
본 논문에서는 크게 Conv 연산의 분해, 정규화 이 두 가지의 Main idea를 통해 계산의 효율성을 모색하고자 하였습니다.
📌 Introduction
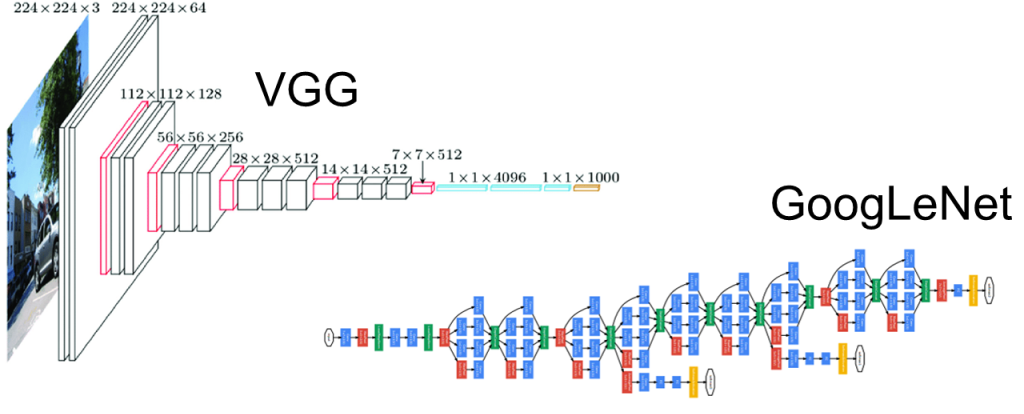
AlexNet이 성공을 거둔 이후, 더 고품질의 시각적 특징을 추출해 다양한 Vision Task에서 성능을 올리고자 시도
-> layer를 깊게 쌓는 VGGNet과 GoogLeNet 등이 등장하였습니다.
VGGNet vs. GoogLeNet
- VGG는 Conv연산과 Pooling 연산의 반복을 통해 아키텍쳐 자체가 단순하다는 장점이 있지만, 높은 연산량이 많다는 단점
- GoogLeNet은 Inception module을 통해 병렬 연산과 차원 축소를 통해 효율적인 연산을 수행할 수 있다는 장점이 있지만, 하지만 이 역시 병렬 처리로 인한 경로의 복잡성과 메모리 관리 차원에서 어려워 layer를 깊게 쌓기에는 한계가 있다는 단점
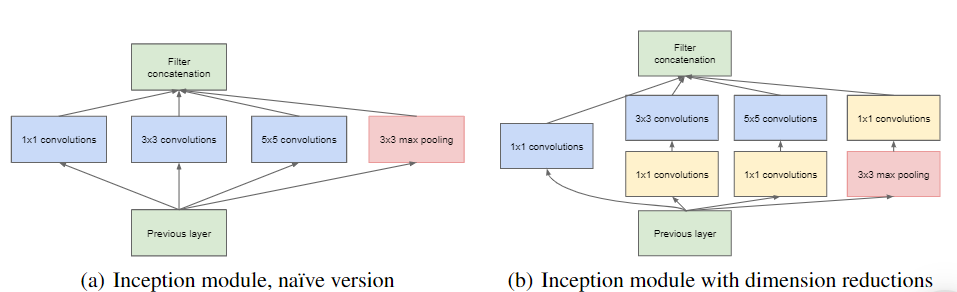
Inception 모듈?
Inception V2,3를 이해하기 위해서는 GoogLeNet에서 등장한 핵심인 Inception의 초기 아이디어를 알아야 할 필요성이 있겠죠.
왼쪽은 다양한 크기의 Conv 필터를 통한 연산과 3*3 max pooling을 병렬로 적용한 Inception 모듈의 가장 basic한 버전이고, 오른쪽은 이에 차원 축소를 적용한 버전입니다.
1. 왜 다양한 크기의 Kernel과 3*3 max pooling을 동시에 진행하는가?
Conv연산의 핵심은 이미지의 다양한 국소적 특징을 추출하는데에 있습니다. 다양한 크기의 kernel을 적용하면 좁은 범위 내에서 질감, 패턴, 선의 형태 등 부분적으로 이미지의 중요 정보들을 추출할 수 있고, 3*3 Max pooling은 이미지 전체 범위에서 각각의 지역적 범위 내의 가장 중요한 정보들을 토대로 이미지를 압축하여 계산량을 줄일 수 있습니다.
-> 한줄로 요약하면, 세부 정보 습득의 정교함 + 전체 이미지 축소를 통한 효율성 확보의 장점이 있습니다.
2. 1*1 Conv연산을 왜 추가적으로 수행하는가?
1*1 Conv 연산은 다양한 효과를 가지고 있습니다.
- 채널수 조정 : 1*1 Conv filter를 각 픽셀에 적용하는 과정에 있어서, filter의 개수를 설정해서 채널 수를 내가 지정한 filter 개수와 동일하게 조정이 가능합니다.
ex) 5*5 *256 이미지에서 1*1 Conv 필터를 64개 사용하면 결국, 256개의 채널 깊이에서 씌워진 창의 가중치 조합에 따라 64개의 정보가 함축된 채널만 가지게 조정되는 것입니다.
- 정보 보존 : 필터 가중치에 따라 중요한 채널의 부분에 조금 더 focus하게 되므로, 의미 있는 정보와 의미 없는 정보에 차등을 두어 정보 손실을 방지할 수 있습니다.
- 비선형성 추가 : 1*1 Conv 연산을 적용한 다음에 비선형 활성화 함수를 연속적으로 적용하기 때문에 복잡한 패턴도 잘 학습합니다.
-> 큰 크기의 filter size에 채널 수까지 많아버리면 연산량 폭발하는데 1*1 앞에 끼워넣으면 채널수 감소에 따른 연산량 감소 효과를 얻을 수 있습니다.
3. Max pooling을 하고 1*1 Conv를 하는 이유는 무엇인가?
먼저 공간 크기부터 줄여서 연산 최적화 부터 하고, 그 안에서 중요 정보를 1*1 Conv 연산으로 보완하는 것이 정석
-> 책을 요약(Max pooling)하고, 그 안에서 또 중요 문장을 추출(Conv 연산)하는 과정은 일반적으로 책 내용을 어느정도 보존하는데, 중요 문장 먼저 추출하고 그 안에서 일부만 남기면 정보 손실이 더 커질 가능성이 있습니다.
본 논문에서는 기존 Inception의 한계를 극복하고, 계산 효율성과 성능 품질 보존 두 마리 토끼를 모두 잡기 위해
인셉션 모듈과 넓게는 CNN의 확장 방식에 관한 최적화 아이디어를 제시합니다.
📌 General Design Principles
Conv Network 설계에 있어서의 일종의 원리, 원칙들을 설명합니다.
1. 특히 네트워크 초기에 발생하는 표현의 병목 현상을 피해라.
병목현상(BottleNeck)은, 네트워크 중간에서 차원을 급격하게 감소시켜 정보의 손실이 발생하는 상황을 의미합니다.
네트워크 초반부에서 저수준 특징을 학습하는데 이에서 손실이 오면, 고수준 특징 추론도 결국 어려워지는 문제가 발생합니다.
정보의 내용은 차원만으로는 판단할 수 없는데, 차원은 각각의 특징을 나타내는 것이고 그 차원간의 상관관계까지 같이 고려해야하기 때문입니다.
ex) 높은 상관성을 가지면 차원 축소를 해도 정보 간 연관성이 있기 때문에 정보가 더 많이 보존되는데, 상관성이 적다면 그냥 쌩정보 하나 그대로 날리는것!
저수준 정보 : 주로 네트워크 초반부에 추출하는 이미지의 엣지, 선 등 기본적이고 단순한 정보
고수준 정보 : 주로 네트워크 후반부에 추출하는 이미지의 종류, 의미 등 추상적인 정보
-> 고양이의 특징을 모르는데, 그 이미지가 고양이인지 어떻게 맞추라는 것인가...
따라서 feature map size를 천천히 점진적으로 줄여나가야하고, 특징 간 상관관계를 고려해야합니다.
2. 더 높은 차원의 표현은 로컬로 처리하기가 쉽다.
작은 차원에서는 똑같은 정보량이라도 더 함축되어 있지만, 높은 차원이면 각각의 특징을 효율적으로 분리할 수 있습니다. 따라서, 손실 함수 최적화가 빨라지고 Gradient 최적점에 빠르게 수렴한다는 장점이 있습니다. (계산량과는 약간 다른 문제 - 한 epoch당 처리해야하는 계산량은 필터 수가 늘기 때문에 늘지만, 몇 epoch 안돌려도 최적으로 수렴)
또한, 비슷 맥락이지만 타일당 활성화 늘리는것(필터 수를 늘려 각 영역에서 더 많은 특징을 학습하는 것)은 특징 간 분리를 잘 수행할 수 있도록 돕습니다.
3. 공간의 집합화는 낮은 차원 임베딩에서 비교적 표현력 손실 없이 수행할 수 있다.
낮은 차원으로 차원 축소를 이전에 진행하게 되면 상대적으로 특징 간 상관관계가 높고 정보가 함축적이기 때문에 Conv 연산이나 풀링 등의 공간 집합화 연산을 하더라도, 비교적 표현력 자체에서 오는 손실이 적습니다. 이는 더 빠른 학습을 촉진시키기도 합니다.
4. 깊이와 너비를 동시에 병렬적으로 증가시켜야 한다.
한정된 자원 안에서 깊이와 너비를 균형있게 병렬적으로 증가 시켜야 최적 성능과 계산량 사이의 밸런스를 달성할 수 있습니다. 깊이는 고수준의 문맥 정보를 탐색할 수 있고, 너비를 키우면 세밀한 국소적 정보의 표현이 풍부해지기 때문일 것입니다.
보이는 것 만큼 간단한 문제는 아니기 때문에, 애매한 상황에서 신중하게 잘 선택해서 사용해야한다고 합니다.(결국 상황에 맞게 잘 쓰라는 것 같네요..)
📌 Factorizing Convolutions with Large Filter Size
GoogLeNet의 성능 향상은 대부분 인접 활성화 끼리 높은 상관관계가 있다는 가정 하에서 적극적으로 차원을 축소한 것에서 왔다고 볼 수 있습니다. 또한 차원 축소, 즉 1*1 Conv연산을 3*3, 5*5 앞에 추가한 것 그 자체를 합성곱 분해로도 볼 수 있다고 합니다.
본 논문에서는 계산 효율성 증가를 위한 다른 합성곱 분해 방법들을 소개 합니다.
합성곱 분해를 하게 되면, 필터 크기가 작아지기 때문에 가중치 수가 적어지게 되어 계산 이득이 발생하고, 빠른 학습이 가능하며 이에서 얻는 계산 이득을 통해서 남는 자원으로 필터 개수를 늘리면서 더 보완적으로 고품질의 세부 정보를 추출할 수 있게 된다는 맥락으로 이해했습니다.
1. Factorization into smaller convolutions

위의 그림이 모든 내용을 대표하여 설명하는 것 같습니다. 결국 5*5 size의 input에 5*5 필터를 적용하게 되면 계산량은 각 활성화 픽셀 하나당 하나의 가중치를 갖기 때문에 5*5 = 25에 해당하고 output feature map이 하나 나오는데, 이를 3*3 필터의 순차적인 두번 적용으로 대체할 수 있다는 것입니다. 결국 5*5에 3*3을 적용하면 3*3이 나오고 거기에 다시 재적용하면 하나의 피쳐맵으로 귀결되기 때문입니다.
그 과정에서 두 가지의 의문이 발생합니다.
[Question]
1. 차원 축소와 합성곱 분해가 표현력 손실을 발생시키는 않는지
2. 분해 사이의 활성화 함수 적용에 있어서 선형 활성화가 좋은지, 비선형 활성화가 좋은지
각각에 대한 정답을 정리하면 다음과 같습니다.
[Answer]
1. 차원 축소와 합성곱 분해는 일반적으로 표현력의 손실이 거의 없이 정보를 효율적으로 압축할 수 있습니다. 하지만 항상 그런 것은 아니며 상관관계가 적거나 비효율적인 설계시에는 손실이 올 수도 있습니다.
2. 분해 중간의 활성화 함수는 실험상 더 고수준 정보 파악할 수 있는, 비선형적 관계 파악할 수 있는 ReLU 쓰는 것이 백번 맞습니다. 아래 그림에서도 관찰할 수 있습니다.

2. Spatial Factorization into Asymmetric Convolutions
3*3 사이즈보다 큰 필터들은 결국 위에서처럼 3*3의 연속으로 분해될 수 있기 때문에 통째로 쓰는 것은 큰 효용이 없습니다. 3*3 역시 2*2 2번으로 분해할 수는 있으나, 계산량 절감이 미미하기 때문에 3*3이 마지노선으로 보는 것이 일반적인 듯 합니다.

그대신 3*3 size의 필터를 비대칭으로 위처럼 3*1, 1*3의 연속 적용으로 보게 된다면, 3*3 = 9에서 3+3=6으로 33프로의 절감 효과를 얻을 수 있다는 것이 장점입니다.
n*n에도 동일한 방식으로 접근하는 것이 가능하지만, 이 비대칭 분해 방식은 초기 layer보다는 12~20 정도의 중간 사이즈 특징 맵에서 잘 작동한다고 합니다.
Q. 왜 초기 layer보다 중간 layer에서 비대칭 분해 방식이 더 적합할까?
3*1, 1*3 이런식으로 따로 떼어서 보는 것은 가로, 세로를 나누어서 특징을 보는 것이라고 할 수 있습니다. 그런데 초기 레이어에서는 선, 질감 등 저수준의 고차원 정보를 다뤄야 하므로 세밀한 정보에서는 방향성 정보가 손실되는데, 중간 부터는 위치 관계 등에 해당하는 전역적 정보를 다뤄야 하기 때문에 가로, 세로의 조합으로도 충분히 설명이 잘 되고 계산 효율성도 지킬 수 있다고 봐주셔야 합니다!
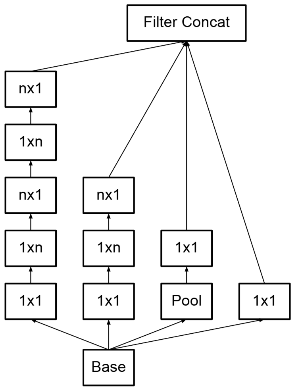
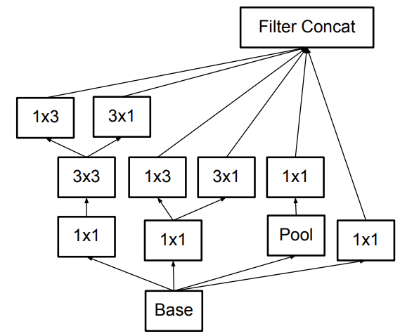
cf) 위처럼 분해 layer를 수직으로 쌓는 것 vs 수평으로 쌓는 것에 대한 고찰
결론적으로, grid는 이미지 처리를 위해 이미지를 일정 사이즈로 나눈 것인데, 17*17 해상도의 grid에서는 8*8보다 크므로 조금 더 전역적인 정보에 집중해야 하기 때문에 가로와 세로를 각각 수직으로 쌓아야하고, 더 낮은 해상도의 grid에서는 세부적인 특징을 보아야하기 때문에 가로 세로를 병렬, 수평으로 쌓아 한번에 정교한 패턴을 확인해야 하기 때문으로 이해해주시면 될 것 같습니다!
📌 Utility of Auxiliary Classifiers

기존 GoogLeNet에서는 인셉션 모듈을 여러 층 깊게 쌓았기 때문에, 기울기 소실 문제가 발생하는 것을 방지하기 위해 중간에 두개의 보조 분류기 구조를 삽입하여 해당 손실량의 일부를 최종 손실에 더해서 학습 과정에만 사용하였습니다. 실제로 당시 전체적인 성능 향상을 확인하였고 보조 분류기의 영향임을 발견하였습니다. (추론에는 사용하지 않습니다)
하지만 본 논문에서 실험한 결과, 초기에는 보조 분류기가 빠른 수렴 효과가 없어서 앞쪽 보조 분류기를 삭제했음에도 큰 영향이 없음을 확인하였습니다. 이는 저수준 특징의 발전에는 큰 의미가 없음을 보입니다.
대신에, 본 논문의 저자들은 보조 분류기에서 배치 정규화와, 드롭아웃 레이어를 넣었을 때 더 나은 성능을 보이는 것으로 미루어 보았을 때 보조 분류기가 정규화 기능으로 작용한다고 주장하였습니다.
📌 Efficient Grid Size Reduction
풀링을 하게 되면, representation bottleneck이 발생하기 때문에 이전에는 차원(채널)을 확장해서 공간 정보에서 오는 손실을 표현력 강화로 보정하고자 하는 시도가 있었습니다. 하지만, 이는 결국 풀링 이전 과정에서 차원을 늘리는 것이기 때문에 계산량이 늘어난다는 단점이 있습니다. 아래의 그림만 보더라도 왼쪽은 bottleneck이 발생하고, 오른쪽은 연산량이 세배가 는다는 양측의 trade-off가 있습니다.

이를 보완하기 위해, 병렬로 stride 2를 가진 풀링 레이어와 conv layer를 사용하면 병목현상을 막으면서, 연산량도 효율적으로 감소시킬 수 있다고 주장합니다.(정보 손실 최소화)

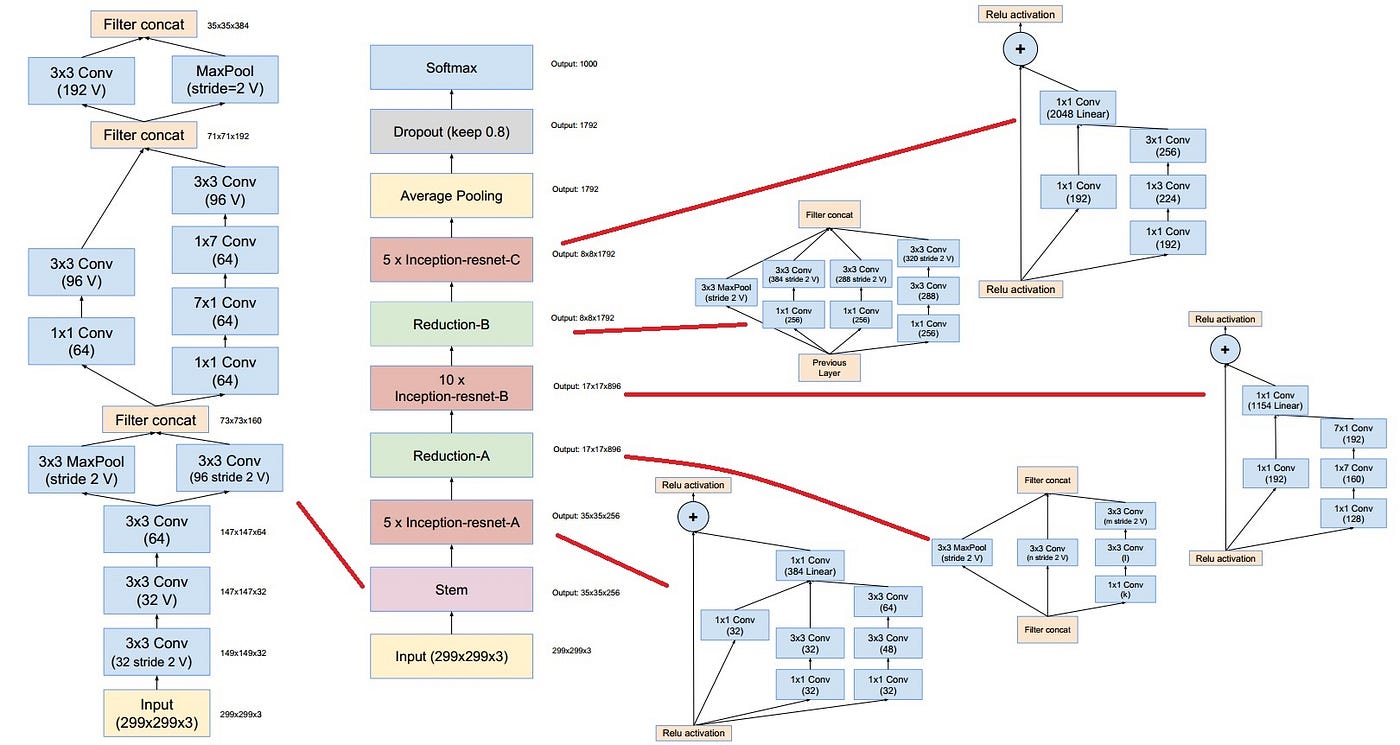
📌 Inception-v2

초기 Inception 모듈 전에 7*7 Conv 필터 연산을 3*3 필터의 연속 적용 세번으로 대체하여 수행하였습니다. stride 2를 적용하는 Conv연산과 pooling을 통해 공간 크기는 지속적으로 줄여나가면서, 고수준 정보 학습을 위해 depth를 지속적으로 키워나가는 모습입니다.
또한, 피쳐맵 크기의 정합성을 유지하기 위해 제로 패딩을 추가로 수행해줍니다.(초기 Conv연산과 Inception 모듈 내에서)
Conv 연산의 반복 적용인 stem 줄기가 끝난 후에, 차례로 figure 5,6,7에 해당하는 Inception 모듈을 각각 3개, 5개, 2개 적용합니다.

각 종류의 Inception 모듈 적용 사이에는 feature map의 크기를 압축하는 과정이 들어가는데, bottleneck을 방지하고 계산 효율성을 동시에 보존하기 위한 위에서 설명한 Grid size reduction 기법이 활용됩니다.
추가로, 중간 Inception B모듈을 적용하는 과정 중 보조 분류기 가지를 추가하여 정규화 효과를 얻고자 하였습니다.
📌 Model Regularization with Label Smoothing
신경망 최종 분류기에서 각 라벨에 대한 확률은 최종 신경망 출력값인 logit에 softmax를 취해 최종 확률을 계산합니다. 이때 negative cross entrophy 손실함수를 활용하게 되는데, 이를 최소화 하도록 모델이 훈련되고 이 과정에서 모델은 실제 라벨값에 해당하는 logit값을 최대화하도록 학습됩니다.

제가 이해한바로는, 결국 모델 입장에서는 만약 정답 레이블의 분포가 1이고 나머지 비정답이 다 0이라면 1에 해당하는 logit값만 확 커지게끔 자동적으로 학습을 하게 되는데, softmax는 결국 상대적 logit 크기를 토대로 최종 확률을 계산하는 것이기 때문에 정답 레이블을 원핫인코딩 할 시에 1에 해당하는 것만 엄청 커지고, 결국 softmax확률도 거의 확신한다 싶을때처럼 확률값이 극대화 된 값에 수렴하기 때문에 과적합이 발생하는 것입니다..(두서없이 말했는데 깔끔한 정리가 어렵네요 ㅠㅠ)
그래서 확신을 방지하고, 모델 학습시에 과적합을 줄일려면 애초에 정답 레이블의 분포 자체를 원핫 인코딩 형태가 아니라 약간의 불확실성을 추가해야 합니다.
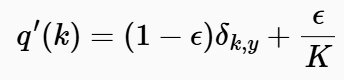
따라서 위의 수식과 같이 스무딩 정도에 해당하는 엡실론을 추가로 지정해서, 실제 1이던 정답값을 1에서 엡실론에서 뺀 후, 해당 엡실론 값의 확률을 나머지 K(클래스 개수)들에게 균등 분배하여 해당 문제를 해결합니다.
이렇게 되면, 모델 학습 과정에서 Logit 값 간 차이를 조금 작게 보정해서, softmax 예측시 약간의 불확실성을 추가할 수 있습니다. 이는 모델의 일반화 능력 향상과 귀결되는 정규화 기법으로 활용됩니다.
📌 Training Methodology
모델의 학습 환경에 대해서 설명합니다.
- 50개의 NVIDIA Kepler GPU를 활용해서 50개 모델 복제본을 한번에 병렬 처리(Tensorflow 활용)
- RMSProp optimizer 활용(감쇠율 0.9, ϵ=1.0)
- 초기 lr 0.045 -> 2에폭마다 0.94배로 감소 , 4에폭때는 0.94의 제곱
- batch size 32로 100 epoch 학습
- 2를 threshold로 gradient clipping
- 모델 평가에는 매개변수의 이동평균을 활용 (이게 잘 이해가 가지 않았는데, 훈련 중에는 가중치 업데이트가 계속적으로 일어나는데, 특정 시점을 딱 사용하는 것보다 파라미터의 과거, 현재 정보를 적절한 간격으로 스무딩해서 사용하면 조금 더 학습을 안정적으로 할 수 있다는 것으로 이해했습니다.)
📌 Performance on Lower Resolution Input
컴퓨터 비전 Task 중 주가 되는 것 중 하나가 탐지 Task인데, 이 때는 보통 고해상도 입력을 받는 것이 더 좋은 성능을 내는 것이 일반적입니다.
다만 본 논문에서는 실험을 하나 진행하였는데, 계산 비용을 고정한 상태에서 해상도만 변경 시킨 경우, 저해상도가 학습 시간은 오래걸리긴 하지만, 결국 최종적으로는 그 간격이 좁혀져 예측 성능은 거의 동일하게 맞춰진다는 결과를 보여줍니다.

결론적으로는, 무슨 말을 하고 싶냐?
자원 여유가 있는데, 빠른 학습이 필요하다 -> 고해상도와 자원 때려 박아서 빠르게 성능 얻자
자원 여유는 없는데, 시간 여유는 좀 있다 -> 모델 조정과 충분한 학습 시간으로 고해상도와 비슷한 좋은 성능 얻자
위의 두가지 형태로 요약해볼 수 있겠습니다.
📌 Experimental Results and Comparisions

여기서는 Inception V3이 무엇인지에 대해 설명합니다.
위의 표에서 각각의 Network는 바로 직전 위의 network에서 하나씩의 요소만 누적해서 추가해가면서 실험을 진행한 것인데, 기본 Inception V2에서 RMSProp, Label Smoothing과 초기 stem 줄기에서 7*7 Conv를 3*3 세번으로 분해한것과 보조 분류기에서 FCN에도 배치 정규화 적용한 것 모두를 적용했을 때 Top1, Top5 오류가 가장 낮고 성능이 좋으며 이 가장 좋은 실험 결과를 Inception V3라고 명명합니다.
또한, 모델 앙상블과 다중 크롭 등의 데이터 증강 기법을 추가적으로 활용한다면 추가적인 성능 개선이 가능함을 시사합니다. (물론 늘어나는 계산 비용은 어쩔수 없지만요..)
📌 Conclusions
Inception V3는 ILSVRC 2012 분류 TASK에서 단일 크롭 평가 기준 당시 State-of-the-art 성능을 달성하였고,
기존 네트워크 대비 약 6배 적은 연산량으로 25% 이상 성능 개선을 달성하였음에 그 의의가 있는 논문인 것 같습니다.
경량화 차원에서 CNN 초기 발전 과정에서 엄청 큰 영향을 주었겠네요..!
앙상블, 증강을 통한 추가 성능 향상 여지도 보였고, 소규모 데이터셋 활용, 저해상도 이미지 처리, 다양한 하드웨어 환경에서의 처리 등 다양한 발전 가능성을 보여 주었던 연구로 정리하면 될 것 같습니다.
📌 느낀점(논문을 읽으면서..)
매우 딥한 고찰들을 이어가면서 논문 리딩을 한게 거의 처음인 것 같은데, 사전 지식이 꽤나 많이 필요했던 것 같고 원리 이해에 많이 애를 먹었던 것 같습니다. 차차 이 부분은 개선이 될 것 같고, 앞으로 양질의 논문 리뷰를 게재하도록 노력해보겠습니다! 틀린 부분이나 제가 잘못 이해한 부분이 있다면 댓글로 적극적으로 훈수해주시고 긴 글 읽어주셔서 감사합니다!
📌References
https://hi-guten-tag.tistory.com/433