LLaVA : Visual Instruction Tuning (Neurips 2023)
Haotian Liu, Chunyuan Li2, Qingyang Wu, Yong Jae Lee
https://arxiv.org/abs/2304.08485
오늘은 LLM과 고성능 이미지 인코더를 Visual Instruction Tuning 방식을 통해 효율적으로 연결해 멀티모달 챗 능력을 가능하게 만든 논문인 LLaVA: Large Language and Vision Assistant를 리뷰해보도록 하겠습니다! 😄
📌 Abstract & Introduction
본 연구는 Visual Instruction Tuning을 통해 범용적인 작업들을 수행할 수 있는 Vision Languge 어시스턴트를 구축하는 작업을 처음으로 시도한 연구입니다.
기존 텍스트 기반 LLM의 instruction tuning은 새로운 작업에서 제로샷 성능을 향상시켰지만, 멀티모달 영역에서는 그 연구가 상대적으로 부족했습니다. 아래는 일반적인 instuction tuning의 한 예시인데, annotation이 되어있지 않은 corpus에 대해 NLI라는 특정 Task를 부여하여 지시문과 응답을 Input과 Output으로 하는 instruction tuning용 데이터셋을 만들고 해당 데이터 샘플들을 활용하여 LLM을 튜닝하는 것입니다.

논문의 저자들은 언어 전용 GPT-4를 활용해 이미지-텍스트 쌍을 instruction-following 형식으로 변환한 고품질 멀티모달 데이터셋을 생성하고, 이를 사용해 CLIP 시각 인코더와 Vicuna 언어 디코더를 연결한 대형 멀티모달 모델인 LLaVA를 만들어 이를 엔드투엔드로 학습시켰습니다.
실험 결과, LLaVA는 보지 못한 이미지와 지시문에서도 멀티모달 GPT-4에 근접한 대화 능력을 보였으며, 합성 멀티모달 명령어 데이터셋에서 GPT-4 대비 85.1%의 상대 성능을 기록했습니다. 또한 과학 분야의 멀티모달 추론 데이터셋에서는 GPT-4와의 앙상블을 통해 SOTA를 달성했습니다.
연구진은 추가로 다양한 Vision Language task를 포함한 LLaVA-Bench 벤치마크를 구축하였고, 생성된 데이터, 코드, 모델, 그리고 시각 챗 데모를 오픈소스로 공개했습니다.
📌 Related Work
Multimodal Instruction-following Agents
기존 컴퓨터 비전 분야의 Instruction-following 에이전트 연구는 크게 두 가지로 구분됩니다.
첫째, 특정 작업별로 개별적으로 엔드투엔드 학습을 수행하는 모델로, 예를 들어 Vision-Language Navigation에서는 시각 환경에서 자연어 지시를 따라 목표를 달성하는 행동 시퀀스를 수행하고, InstructPix2Pix는 입력 이미지와 텍스트 지시를 바탕으로 이미지를 편집하는 역할을 수행하기도 합니다.


둘째, LangChain이나 LLM을 활용해 여러 모델을 조율하는 시스템으로, Visual ChatGPT, X-GPT, MM-REACT, VisProg, ViperGPT 등이 이에 해당합니다.
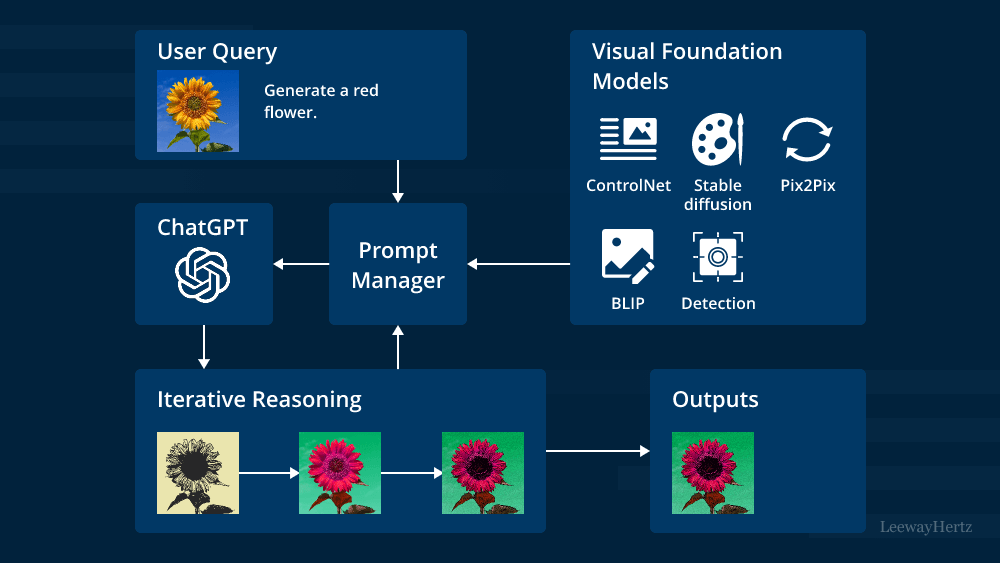
본 연구에서는 이러한 접근들 중에서도 하나가 아닌 다양한 작업을 수행할 수 있는 엔드투엔드 학습 Vision-Language 멀티모달 모델 개발에 집중합니다.
Instruction Tuning
NLP 분야에서는 GPT-3, T5와 같은 LLM에 instruction tuning을 적용해 제로샷 및 퓨샷 일반화 성능을 향상시킨 사례가 많습니다. 대표적으로 InstructGPT, ChatGPT 등이 있으며, 단순한 지시 기반 학습이 LLM 성능을 크게 높일 수 있음이 입증되었습니다.
이 아이디어는 자연스럽게 비전 분야로 확장되었고, 그 예로 Flamingo는 멀티모달 분야에서 제로샷 전이와 In-context Learning에서 뛰어난 성능을 보였습니다.
또, 당시 OpenFlamingo와 LLaMA-Adapter가 LLaMA에 이미지 입력 기능을 추가하는 오픈소스 시도를 진행하며 멀티모달 LLM 개발의 기반을 마련했지만, 기존 모델들은 비전-언어 명령어 데이터로 명시적 튜닝을 거치지 않아 멀티모달 작업에서 언어 전용 작업 대비 성능이 낮았습니다.
이에 본 연구는 해당 공백을 메우는 것을 목표로 Visual Instruction tuning을 시도했고, 이는 prompt tuning 방식과는 달리 모델의 지시 수행 능력을 높이는 데 중점을 둔 방식입니다.
📌 GPT-assisted Visual Instruction Data Generation

연구진은 일반 태스크에 비해 멀티모달 Instruction Following dataset의 양이 부족하다는 문제를 해결하기 위해, GPT-4, ChatGPT를 활용한 자동 데이터 생성 파이프라인을 제안하였습니다.
기존 CC, LAION, COCO 등 공개 이미지-텍스트 쌍을 활용하되, 단순히 캡션을 지시문 응답 형식으로 변환하는 방식은 다양성과 심층 추론이 부족하다는 한계를 지적합니다. 이를 보완하기 위해 이미지를 위의 그림처럼 캡션과 바운딩 박스 정보로 구성된 기호적 표현으로 변환하여, 텍스트 입력만 가능한 GPT-4가 시각적 내용을 이해할 수 있도록 설계했습니다.
이후 소수의 인간 작성 예시를 시드로 제공해 In-context Learning을 유도하고, 세 가지 유형의 데이터셋을 생성했습니다. 첫째, 객체의 종류, 개수, 행동, 위치 등 명확한 답변이 가능한 시각 질의응답 대화 데이터, 둘째, 장면에 대한 풍부하고 포괄적인 설명을 생성하는 상세 설명 데이터, 셋째, 단계별 논리 전개가 필요한 복합 추론 데이터가 그 세가지 입니다.
최종적으로 총 15.8만 개의 고유 샘플들을 확보했으며, 비교 실험에서는 GPT-4가 ChatGPT보다 공간 추론과 응답 품질에서 일관되게 우수함을 확인하였다고 합니다.
📌 Visual Instruction Tuning

Architecture
LLaVA는 사전학습된 LLM과 Vision 모델의 능력을 모두 활용하는 구조로 설계되었습니다. LLM으로는 공개 체크포인트 중 지시문 수행 능력이 뛰어난 Vicuna를 베이스로 선택했고, 시각 인코더로는 CLIP ViT-L/14를 사용하여 이미지 특징을 추출합니다. 추출된 시각 특징은 학습 가능한 Projection 행렬 W를 통해 LLM의 단어 임베딩 공간과 동일한 차원의 시각 토큰 시퀀스로 변환됩니다.
단순 투영을 통한 모달리티 연결은 경량 구조이어 때문에 빠른 데이터 중심 실험이 가능하고, 본 논문에서는 Flamingo의 gated cross-attention이나 BLIP-2의 Q-former와 같은 더 정교한 결합 방법은 향후 연구로 남겨두었습니다.
Training

먼저, 각 이미지에 대해 멀티턴 대화 데이터를 생성합니다 X = (1번질문, 1번응답, 2번질문, 2번응답 ... T번 질문, T번 응답)와 같은 형식입니다. t번째 턴에서의 지시문은, t=1이라고 가정했을때는 (질문과 이미지), (이미지, 질문) 중 하나이고, t가 그 이상이라고 가정했을때는 해당 턴의 질문에 해당합니다.
이를 통해서 위의 그림과 같은 통합 형식의 시퀀스를 구성할 수 있습니다. LLM은 원래의 auto-regressive 학습 목표를 유지한 채, 예측 토큰에 대해 instruction tuning을 수행합니다.
시퀀스 길이를 L이라고 했을 때 목표 답변 확률 Xa의 확률은 다음과 같이 수식으로 표현됩니다.
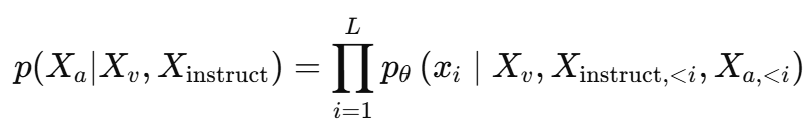
추가로, 학습 단계를 아래 두 단계로 나타낼 수 있습니다.
- 특징 정렬 사전학습 : CC3M에서 59.5만 개의 이미지-텍스트 쌍을 필터링하여 single turn instruct following 데이터로 변환하고, 시각 인코더와 LLM은 동결한 채 투영층에 해당하는 W만 학습하여 이미지 특징을 LLM 임베딩 공간에 효과적으로 정렬하는 단계입니다.
- 엔드투엔드 파인튜닝 : 시각 인코더를 고정한 상태에서, 투영층 W와 LLM 파라미터를 함께 업데이트하는 과정입니다. 이 과정은 두 가지 시나리오로 수행되는데, 첫째는 15.8만 개의 Vision language instruction 데이터로 멀티모달 챗봇을 학습하는 것이고, 둘째는 ScienceQA 데이터셋을 활용해 질문 및 컨텍스트를 지시문으로, 추론 및 정답을 응답으로 구성하여 과학 도메인에서의 멀티모달 질의응답 능력을 강화하는 것입다.
📌 Experiments
연구진은 LLaVA의 명령어 수행 능력과 시각적 추론 능력을 각각 멀티모달 챗봇과 ScienceQA 데이터셋 두 가지 주요 실험 설정에서 평가하였습니다.
[Setting]
자원 : 8 × A100 GPU
학습 파라미터 : Vicuna의 하이퍼파라미터를 따라 학습
사전학습 : 필터링된 CC-595K 서브셋에서 1 epoch 동안 수행
사전학습 lr : 0.002
사전학습 Batch Size = 128
파인튜닝 : LLaVA-Instruct-158K 데이터셋으로 3 epoch 동안 수행
파인튜닝 lr : 0.00002
파인튜닝 Batch Size = 32
Multimodal Chatbot

LLaVA는 약 8만 장의 이미지로 학습한 소규모 멀티모달 instruction tuning 모델임에도 GPT-4와 유사한 수준의 시각 이해, 추론 성능을 보였습니다. BLIP-2와 OpenFlamingo가 주로 이미지 묘사에 집중하는 반면, LLaVA는 지시를 따라 적절한 답변을 생성하는 능력이 뛰어난 것을 확인하였습니다.
정량적 평가도 동시에 수행하였는데, 이미지,정답 캡션,질문으로 구성된 데이터셋을 기반으로, 텍스트 전용 GPT-4를 기준 모델로 삼아 후보 모델의 응답을 유용성, 관련성, 정확성, 세부 수준에서 1~10점으로 평가했습니다. 평가 사유도 상세히 기술하도록 하며, 모델 성능을 평가하기 위해 두 가지 벤치마크를 만들었습니다.
먼저 LLaVA-Bench (COCO) 입니다. COCO-Val-2014에서 무작위로 30장의 이미지를 선택하고, 각 이미지에 대해 대화, 상세 설명, 복합 추론 질문을 각각 생성하여 총 90개의 질문을 만들었습니다.

instruction tuning을 적용하면 사용자 지시 수행 능력이 50포인트 이상 크게 향상됨을 확인했고, 상세 설명 및 복합 추론 질문을 소량 추가하는 것만으로도 모델의 전반적인 능력이 7포인트 향상됨을 확인할 수 있었습니다. 최종적으로 세 가지 데이터 유형을 모두 사용했을 때 성능이 최고치를 기록하였습니다.
다음으로 LLaVA-Bench (In-the-Wild) 입니다. 더 어려운 작업과 새로운 도메인 일반화 능력을 평가하기 위해, 실내,실외 장면, 밈(, 회화, 스케치 등을 포함하는 24개의 다양한 이미지를 수집하고, 각 이미지에 대해 수작업으로 작성한 상세 설명과 적절한 질문을 포함해 총 60개의 질문을 구성했습니다.

위의 결과 표를 보았을 때, instruction tuning 덕분에 LLaVA는 BLIP-2 대비 +29%, OpenFlamingo 대비 +48%의 성능 향상을 보인 것을 관찰할 수 있고, 텍스트 전용 GPT-4와 비교했을 때, LLaVA는 복합 추론 질문에서 81.7%라는 좋은 성능을 달성한 것을 볼 수 있습니다.
다만 LLaVA는 특정 상황에서 다국어 이해, 폭넓은 지식 보유, 고해상도 이미지 세부 인식, 복합 의미 해석 능력에는 때때로 한계를 보였습니다. 예를 들어, 라면 사진에서는 식당 이름과 반찬을 정확히 파악하기 어려웠고, 냉장고 사진에서는 요거트 브랜드를 구별하지 못했습니다. 또한 “딸기맛 요거트가 있는가”라는 질문에 실제로는 요거트와 딸기가 따로 있음에도 ‘예’라고 답하는 등, 이미지를 단편적인 패치 집합으로 인식해 복합적 문맥을 놓치는 문제가 나타났습니다.
ScienceQA
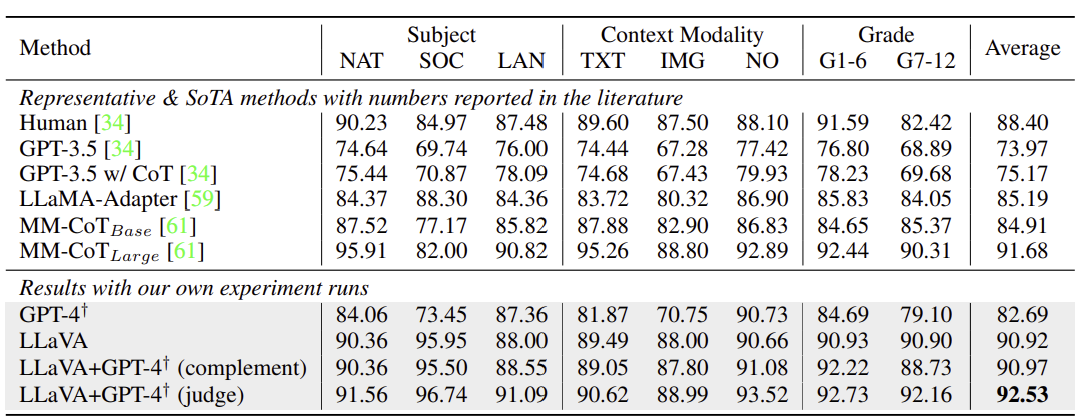
ScienceQA 실험에서 LLaVA는 시각 피처를 활용해 이유를 먼저 예측한 뒤 답을 제시하는 방식으로 학습하여 SoTA에 거의 근접한 성능을 보였습니다. 또, GPT-4를 단독 사용하면 GPT-3.5 대비 성능이 크게 향상되었으나, 이미지나 그래프가 부족하다는 이유로 답변을 포기하는 경우가 많았습니다. 이를 보완하기 위해 LLaVA와 GPT-4를 결합한 결과, GPT-4 판정 방식을 사용했을 때 모든 질문 유형에서 성능이 향상되어 SoTA를 달성했습니다.
특히, 이미지가 필요 없는 문제에서는 GPT-4가 LLaVA의 오류를 수정해 성능을 끌어올리는 효과를 보였습니다. 이는 GPT-4를 모델 앙상블에 활용한 첫 사례였습니다.
추가적으로 Ablation Study를 진행하였습니다.

가장 먼저 시각 Feature 추출 시, 가장 마지막 레이어보다 그 전 레이어를 사용할 때 성능이 더 좋았는데 전역적 특성 대신 세부 이미지 이해에 유리한 국소적 특성을 더 잘 반영하기 때문으로 추측되었습니다. 또한, CoT형 이유를 먼저 답변에 포함시키는 전략은 수렴 속도를 크게 높이지만 최종 성능 개선에는 제한적으로 답변 우선 전략과 큰 차이가 없음을 보였습니다.
다음으로, 사전학습을 건너뛰고 ScienceQA만으로 학습 시 정확도가 낮아져 사전학습이 멀티모달 특징 정렬과 기존 지식 유지에 중요함을 보여주었으며, 마지막으로 7B 모델이 동일 조건에서 13B 모델보다 정확도가 낮아, 모델 규모가 성능 향상에 기여함을 입증하였습니다.
📌 Conclusion
본 논문에서는 Visual Instruction Tuning의 효과를 실증적으로 보여주었습니다. 저자들은 Vision Language Instruction Following 데이터셋을 자동으로 생성하는 파이프라인을 제안하였고, 이를 활용해 LLaVA라는 멀티모달 모델을 학습시켰습니다.
LLaVA는 ScienceQA 데이터셋으로 파인튜닝 시 새로운 SOTA 정확도를 기록했고, 멀티모달 대화 데이터셋으로 학습했을 때 우수한 시각 대화 능력을 보였습니다. 또한, 멀티모달 Instruction Following 성능을 평가하기 위한 첫 벤치마크를 구축했다는데 그 의의가 있습니다.
종합해보자면, 해당 연구는 범용적인 Vision Language task를 지시하고 효율적으로 수행할 수 있는 어시스턴트 개발의 초기 시도이며, 향후 보다 강력한 멀티모달 모델 개발을 위한 뼈대를 제공하는 연구였습니다.
📌 느낀점(논문을 읽으면서..)
사실, 기존에 읽었었던 아키텍쳐 기반의 VLM 모델들 보다는 기존에 LLM 분야에서 좋은 성과를 거두었었던 Instruction tuning을 비전 작업에 맞게 적용하고 조금 변형한 시도에 해당하는 논문인 것 같은데, 그래서인지 완전 신기하다의 느낌은 아니긴 했지만, 다만 한가지 생각이 명확하게 들었던 것 같습니다.
좋은 파운데이션 기술이 나올때마다 그 장점과 단점에 대해 빠르게 명확히 이해하고 여러 다른 도메인에 적용시켜보고 그 성능을 확인하는 통찰력과 아이디어가 매우 중요함을 느끼게 해주었던 논문인 것 같습니다.
📌References
https://kimjy99.github.io/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0/llava/