Mask R-CNN (2018.01.V3)
Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick(Facebook AI Research)
https://arxiv.org/abs/1703.06870
오늘은 기존 객체 탐지 방법론인 Faster R-CNN에 Segmentation Task를 추가함으로써, 모델의 성능과 범용성에 대해 추가적 개선 여지를 보여준 Mask R-CNN 모델에 대해 알아보도록 하겠습니다. 바로 논문 리뷰 시작하겠습니다! 😁
📌 Abstract & Introduction
당시 객체 탐지와 Sematic Segmentation 분야는 성능 개선을 비교적 빠른 시간에 이루었고, 이는 기존의 Fast, Faster R-CNN 모델과, FCN의 기여가 컸다고 합니다. 본 논문에서는 기존의 Segmentation Task에서 더 나아가 Instance Segmentation을 위한 효과적인 방법론 제시를 그 목적으로 하고 있습니다. 연구 목적 달성을 위해 저자들은 Mask R-CNN 이라는 기존 Faster R-CNN의 변형 형태 모델을 고안하여 소개합니다.
Semantic Segmentation vs. Insatance Segmentation
Sematic Segmentation은 이미지의 각 픽셀이 어떤 클래스에 대해 Binary하게 포함되는지 안되는지 그 여부만 따지는 Task로, 같은 Class의 Object들에 대해서는 서로 구분지을 수 없다는 한계점이 존재합니다.
Instance Segmentation은 위와 다르게 이미지 내부에서 개별 객체 탐지와 Semantic Segmentation을 결합함으로서 클래스 단위가 아닌 객체 단위로 물체를 탐지하고 각 객체의 클래스를 추론하는 Task입니다. 즉, 같은 클래스에 속하더라도 서로 다른 객체라면 이까지 구분해낼 수 있습니다.

기존 Faster R-CNN 에서는 각 RoI 관심 영역에 대해 빨간색 박스 부분에 해당하는 Class Prediction과 Bbox Regression 두 개의 개별 작업만 수행하였다면, Mask R-CNN에서는 아래에 파란색 박스 부분에 해당하는 마스킹을 위한 FCN 브랜치를 하나 더 추가함으로써 Faster R-CNN을 확장합니다. 이를 통해 Bbox 내에서 각 픽셀이 객체에 해당하는지 해당하지 않는지 추가로 판단할 수 있습니다. 기존 두 브랜치와 동시 동작하기 때문에 픽셀 단위의 객체 탐지, 그리고 각 객체의 Class 분류까지 동시에 할 수 있게 되는 것이죠!

또한 기존에는 Feature Map에서 추출된 각 RoI들을 서브 레이어에 입력하기 위해 RoI Pooling 방식을 활용하였다면, 본 논문에서는 정확한 위치정보의 보존을 위해 위의 그림에서와 같이 양자화가 이루어지지 않는 RoI Align 방식으로 변경하여 다음 네트워크에 입력으로 전달할 수 있도록 전체 Architecture를 설계하였습니다. 두 가지 방식 각각에 대해서는 아래에서 조금 더 자세히 설명하도록 하겠습니다.
이렇게 위의 두 가지 요소를 변형함으로서 만들어진 Mask R-CNN은 COCO Dataset의 Instance Segmentation과 Object Detection 벤치마크에서 각각 당시 SOTA를 달성하였습니다. 이후 인간의 Key-Point 데이터셋으로 Pose Estimation 실험을 추가적으로 진행하였는데, 이 역시 SOTA를 달성하여 다른 Task로의 범용적인 접근 가능성도 보여주었습니다.
📌 Related Work
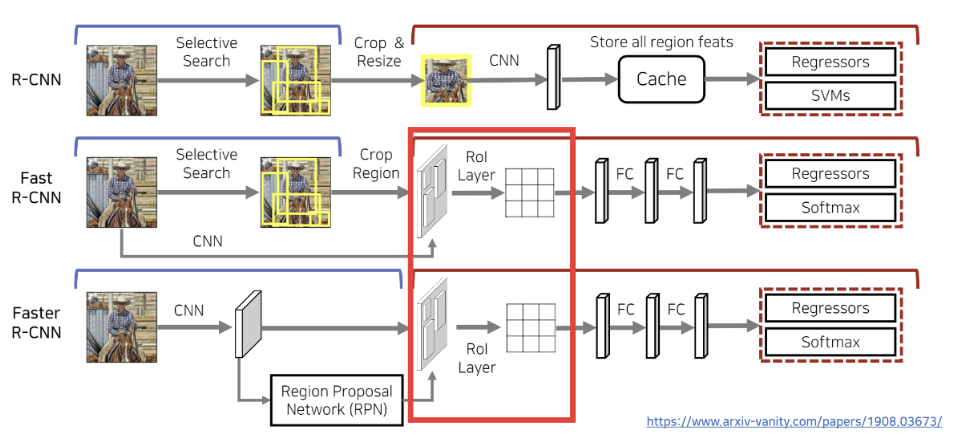
R-CNN 계열 모델들의 발전사를 다시 한번 다루고 있습니다. R-CNN은 후보 영역별로 독립적인 CNN Network를 실행하는 메커니즘이기 때문에 복잡도면에서 경쟁력이 매우 떨어지는 모델이고, 이 한계를 극복해나가는 과정에서 뒤의 두 가지 모델이 순차적으로 등장하였습니다.
두 모델은 기존의 Selective Search를 통해 Input Image에 대해 후보 영역을 생성하는 것과, 독립적인 RPN이라는 네트워크를 학습시켜 Feature map에 대해 후보 영역을 생성한다는 점에서 서로 다릅니다.
하지만 사실 그것보다는 본 논문과의 차이점에 주목할 필요가 있는데, 두 모델 모두 공통적으로 피쳐맵에 위치한 각 RoI들을 뒤의 Fully Connected Layer에 전달하기 위해 단순 Max Pooling 기반의 RoI Pooling을 사용하였다는 것입니다.
Instance Segmentation 분야에서 Mask R-CNN가 나오기 이전 기존 접근 방식은 전반적으로 이미지 전체에 대한 Segmentation을 먼저 진행하고 이후 객체 탐지를 진행하는 방식으로, 대표적으로 DeepMask같은 방법론들이 있었습니다. 하지만, 이는 속도가 느리고 객체 경계를 정확히 구별하지 못해 성능이 낮았습니다. 특히나 중첩된 객체를 정확히 구분해내지 못하는 점이 두드러졌습니다.
하지만, Mask R-CNN은 객체를 먼저 감지하고 이후 Segmentation을 진행하는 Instance-First Approach로 더 정확하고 빠르게 Instance Segmentation을 수행할 수 있게 되었습니다.
📌 Mask R-CNN
앞선 Intro에서 잠시 설명했던 것과 같이, Mask R-CNN은 기존 Faster R-CNN의 확장 버전으로, Faster R-CNN에 대한 반복적인 설명은 여기서 생략하도록 하겠습니다.
Mask R-CNN
Mask R-CNN은 Faster R-CNN의 RPN + (클래스 & 박스 오프셋 예측)과 같이 전체 틀 자체는 동일한 두 단계를 채택하면서도 뒷 단계에서 각 RoI에 대한 Binary Mask 출력 작업까지 추가하여 진행함으로서 Instance Segmentation을 위한 약간의 변형을 가한 것으로 볼 수 있겠습니다.
따라서 Mask R-CNN에서는 다중 Loss를 \(L = L_{\text{cls}} + L_{\text{box}} + L_{\text{mask}}\)로 정의합니다. 이 Loss는 기존 분류 및 바운딩 박스 손실에 단순히 마스크 손실을 추가한 형태이고, 마스크 가지는 각 RoI에 대해 \(K \times m^2\)의 출력을 가지게 됩니다. K개의 클래스 각각에 대해 \(m \times m\) 해상도의 이진 마스크를 인코딩하기 때문입니다.
이것을 구현하기 위해 픽셀별로 시그모이드 함수를 적용하고, 마스크 손실을 Binary Cross Entropy Loss의 평균으로 정의합니다. 또한 클래스 k와 연결된 RoI에 대해 마스크 손실은 오직 k-번째 마스크에서만 정의되어, 다른 클래스의 영향을 받지 않도록 설계되었습니다. 클래스 예측과 마스크를 분리함으로서 클래스 간 경쟁을 억제할 수 있게 되는 것입니다.
Mask Representation
기존 객체 감지에서는 클래스 레이블과 바운딩 박스 오프셋을 예측할 때 Fully Connected Layer를 사용합니다. 하지만 이 방법에서는 입력을 1차원 벡터로 축소하기 때문에, 객체의 공간적 구조를 보존할 수 없다는 한계가 있습니다.
마스크에서 픽셀 단위 이진 분류를 수행하기 위해서는 원본 공간 구조를 유지하는 것이 중요한데, 본 논문에서는 Fully Convolutional Layer를 활용함으로서 그 부분을 해결하였습니다. Conv연산은 마스크 연산에 FC Layer를 적용하는 것에 비해 연산량도 적고, 성능도 좋습니다.
RoI Align
기존 객체 탐지에서는 RoI Feature map을 FC Layer에 태우기 위해 RoI Pooling을 수행합니다. 객체 탐지에서는 소수점 단위의 정확한 위치정보 표현이 그다지 중요한 요소는 아니었기에, RoI Pooling에서는 만약 픽셀 좌표가 소수점 단위라면, 이를 Quantization, 즉 반올림하여 정수로 매핑하는 방식을 활용합니다.

최종적으로는 아래 두번째 그림과 같이 반올림된 RoI를 지정된 크기의 서브셀로 나눈 후 각 그리드 안에서 Max Pooling을 진행하여 최종 Output을 얻게 되는 형식을 따릅니다. 하지만 이 경우, 픽셀 단위의 정교한 위치 정보를 요하는 Instance Segmentation 작업에서는 Quantization 방식이 위치 정보의 왜곡을 불러일으킵니다. 따라서 이러한 한계를 극복하기 위해 본 논문의 저자들은 RoI Pooling 대신 RoI Align 방식을 활용합니다.

RoI Align은 기본적으로 Quantization을 철저히 배제한 방식입니다. 우선적으로 피쳐맵에 투영된 특정 RoI를 추출한 후, RoI를 지정된 크기의 그리드 셀로 등분합니다. 아래 예시는 3*3의 하나의 예시이고, 크기는 고정되지 않습니다. 2*2도 될 수 있고, 4*4도 될수 있습니다. 이후 각 그리드 셀의 가로 세로 3등분 지점들의 교차점에 해당하는 4개의 Sampling Point를 아래 그림과 같이 구성합니다. ex) (9.94, 6.50), (10.64, 6.50), (9.94, 7.01), (10.64, 7.01)

이후, 각 Sampling Point마다 인근의 가장 가까운 4개의 셀 중심점을 결정하여 이를 통해 Bilinear interpolation을 수행합니다. 이때 Sampling Point는 당연한 이야기이겠지만, 반드시 네 중심점으로 이루어진 사각형 내부에 위치해야합니다.
Bilinear interpolation을 알기 위해서는 Linear interpolation, 선형 보간에 대해 먼저 알 필요성이 있는데요, 선형 보간은 두 점 p1,p2 사이의 어떤 p점의 값을 유추할 때 p1,p,p2 점이 선형적 관계를 가진다고 가정하고, 거리 비와 양쪽 값을 이용하여 값을 유추하는 방식입니다.

Bilinear interpolation은 Linear interpolation을 1차원에서 2차원 평면으로 확장한 방식으로, B와 C, A와 D를 선형 보간하여 얻은 V와 U를 한번 더 선형 보간하여 2차원 평면 내 ABCD 좌표 사이의 점 P의 값을 구하는 방식입니다.

수식은 아래와 같습니다.
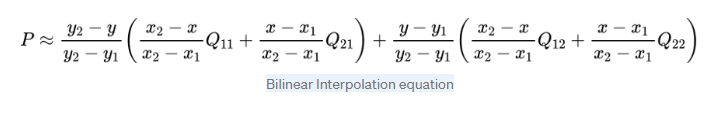
결론적으로 RoI Align의 전체 과정을 종합해보자면, 위에서 하나의 셀별로 찾은 4개의 Sampling Point 마다 각각 4개의 인근 셀 중심점을 찾고, 이 지점들을 통해 이중 선형 보간을 반복적으로 수행하여 셀 당 총 4개의 값을 얻습니다. 그리고 이에 Max Pooling을 적용하여 해당 셀의 실수 형태의 대표값을 얻습니다. 이를 모든 셀에 대해 반복하는 과정으로 전체 과정이 이루어집니다.

이러한 방식으로 RoI Align은 별다른 Quantization 없이, 정보의 손실 없이 Pooling을 진행할 수 있게 되는 것입니다.
Network Architecture
접근 방식의 일반성을 보여주기 위해 본 논문의 저자들은 Mask R-CNN을 여러 아키텍쳐로 구현하였습니다.
또한, 전체 이미지 특성 추출에 활용되는 CNN 백본과 각 RoI에 대해 별도로 적용되는 바운딩 박스 분류 및 회귀, 그리고 마스크 예측을 위한 네트워크 헤드를 구분하였습니다.
백본 아키텍쳐를 네트워크 깊이 - 특징의 형태로 네이밍하며, 가장 먼저 50, 101 레이어의 ResNet, ResNeXt를 평가합니다. 이때 모델 이름 뒤에 C4가 더 붙는데, 이는 기존 Faster R-CNN에서 ResNet을 활용할때 ResNet 4단계의 마지막 Conv Layer에서 특성을 추출했기 때문에 이러한 이름이 추가로 부여됩니다. ex) ResNet-50-C4
추가로 저번 EfficientNet에서 잠시 살펴 보았던 FPN 피라미드 네트워크를 고려하였는데, 서로 다른 수준에서 RoI 피쳐맵을 추출하기 때문에 ResNet-FPN 백본은 정확도와 속도 면에서 모두 좋은 이점을 부여한다고 합니다.
헤드의 경우에는, 기존 ResNet-C4 기반 Faster R-CNN에서는 C4에서 Feature를 추출한 뒤, 즉 C4까지 백본으로 활용한 뒤, 헤드 연산은 C5에서 진행을 하게 되는데 C5는 ResNet 최종 Conv 블록으로 연산량이 매우 많기 때문에 연산량이 많다고 합니다. 하지만, FPN 기반에서는 C5까지 이미 백본에 포함되어 들어가기 때문에 연산 측면에서 효율적으로 별도의 가벼운 헤드를 설계하여 사용할 수 있다는 장점이 있다고 합니다.
Training & Inference
Training : Faster R-CNN에서와 같이, RoI는 Ground truth와 0.5이상의 IoU를 가질 때 양성으로 간주되고, 이외에는 음성으로 간주되며, 마스크 손실은 양성 RoI일 때만 정의된다고 합니다. 마스크는 RoI와 Ground truth의 겹치는 부분을 목표로 합니다.
[세부 학습 설정]
- 이미지 중심 훈련(하나의 이미지에서 여러 RoI를 샘플링하여 학습)
- 이미지 Resize(짧은 변이 800 픽셀이 되도록 조정)
- 미니 배치 구성(각 GPU당 2개 이미지 사용, 각 이미지당 양성:음성 비율 1대 3으로 하여 N개 샘플링)
-> C4 백본의 경우 N=64, FPN 백본의 경우 N=512
- 8개의 GPU 사용
- 초기 lr = 0.02에서 120000번 반복 후 10배 감소하여 총 160000 step 진행
- weight decay = 0.0001
- momentum = 0.9
- ResNeXt 백본 사용시 GPU당 1개 이미지, 초기 lr = 0.01로 조정
- RPN은 5개 스케일과 3개 비율을 사용하고, Mask R-CNN과 독립적으로 훈련
- RPN과 Mask R-CNN 간 백본 공유 가능
Inference : C4 백본은 300개의 RoI를 활용하고, FPN 백본은 1000개의 RoI를 활용합니다. RoI Align으로 사이즈 조정이 끝난 각 피쳐맵에 대해 바운딩 박스 예측을 수행하고, NMS를 통해 상위 100개의 RoI 박스만을 남깁니다.
이 상위 100개의 박스를 가지고 마스크 예측 브랜치에서 작업을 수행하고, 분류 브랜치에서 최종 분류된 클래스에 해당하는 마스크만 사용합니다. m*m 사이즈의 마스크를 RoI 사이즈로 조정하고, 픽셀별 이진 분류를 통해 최종 마스크를 생성하는 과정으로 마무리됩니다.
NMS를 통해 걸러진 최종 100개의 박스만 사용하기 때문에, 마스크 예측 작업을 추가적으로 수행했음에도 더해지는 계산량 자체는 크지 않다는 것이 특장점으로 볼 수 있겠습니다.
📌 Experiments
성능 평가는 COCO Dataset에서 기존 SOTA를 달성했던 모델들과 MASK AP 비교를 통해 진행하였습니다.
80k의 train image와 35k의 val image subset을 통해 학습을 진행하였고, 성능 평가는 나머지 50k의 val image로 진행하였다고 합니다.
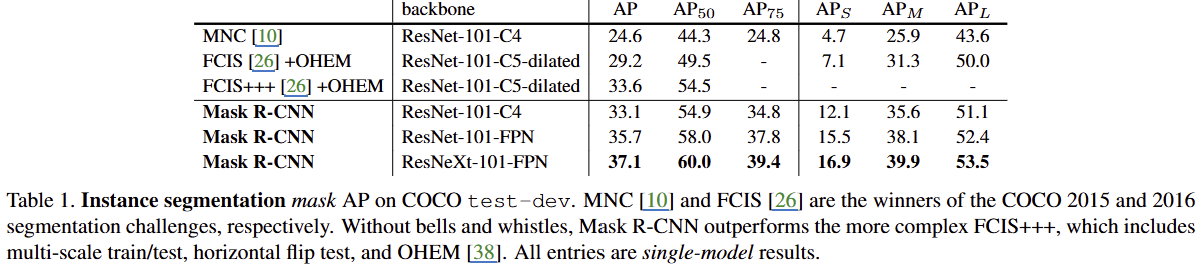
Mask R-CNN은 Multi-scale train/test, Horizontal flip test, Online hard example mining을 다 포함해서 기존 SOTA였던 FCIS+++의 성능을 앞서는 결과를 보였습니다. 아래의 그림을 보면, FCIS는 상대적으로 Overlapping된 물체에 대해 마스크 예측을 잘 수행하지 못할 때도 있지만, Mask R-CNN은 이러한 지점에서 성능이 좋습니다.

Ablation Experiments

본 논문의 저자들은 추가 Ablation Study를 진행하였습니다. 주요 특징별로 살펴보도록 하겠습니다.
백본 아키텍쳐 : (a)를 보았을 때, 백본 네트워크의 레이어가 깊을 수록 더 좋은 성능을 보임을 알 수 있습니다.
마스크 예측 : (b)를 보았을 때, 클래스의 간섭 없이 sigmoid 기반으로 객체 유무에 대한 이진 분류 수행이 클래스의 간섭이 있는 softmax 다중 분류보다 더 성능이 좋은 것을 알 수 있습니다.
RoI Align : (c)를 보았을 때, 백본 네트워크를 통일하여 RoI 조정 방식 자체만 놓고 결과를 보면 RoIAlign 방식이 가장 성능이 좋은 것을 볼 수 있습니다. 추가로 RoIWarp 방식도 bilinear sampling을 쓰지만, 여전히 양자화를 활용하기 때문에 성능이 상대적으로 좋지 않다고 합니다.
Mask Branch : (e)를 보았을 때, 마스크 브랜치에는 멀티 레이어 퍼셉트론 기반의 Fully-Connected Layer를 사용하는 것보다 Conv layer를 활용하는 것이 상대적으로 더 성능이 좋은 것을 관찰할 수 있습니다.

더불어, 위의 표에서 볼 수 있듯이 Mask R-CNN은 Instance Segmentation 이외 기본 객체 탐지 Task에서도 기존 SOTA를 마킹하던 Faster R-CNN 변형 모델들의 성능을 뛰어 넘은 것을 볼 수 있습니다.
마지막으로, Mask R-CNN은 당시 기준으로 Inference time 최적화를 하지 않아서 추가 개선 여지가 있음을 밝혔고 저자들이 주장하기로는 학습 속도도 빠르다고 주장합니다.
Mask R-CNN for Human Pose Estimation
모델의 범용성을 입증하기 위해 본 논문의 저자들은 인간의 자세 추정 Task에도 추가적으로 모델을 적용하여 실험을 진행하였습니다.
인간의 어깨나 관절 등 주요 키포인트가 되는 K개의 지점 각각에 대해, 오직 하나의 픽셀만 앞쪽으로 표시되는 m*m 크기의 이진 마스크를 크로스 엔트로피 손실이 최소화되는 방향으로 학습합니다. 각각의 키포인트들은 독립적으로 처리되며, 본 논문에서는 ResNet-FPN 백본을 활용하고 아래 그림과 같은 헤드 구조를 사용하였다고 합니다.

아래 그림과 같이 Mask R-CNN은 Key Point Detection 분야의 COCO Dataset 벤치마크에서 2016 우승자보다 더 좋은 성능을 달성하였습니다. 또한 이 모델을 통해 바운딩 박스 예측, 마스크 예측, 키포인트 예측을 동시에 수행할 수 있는 프레임워크를 발견하였다는데 그 의의가 있다고 합니다.

마지막으로, 이쯤에선 당연한 이야기이겠지만 키포인트 예측도 픽셀의 정밀도가 매우 중요하기 때문에 RoI Align 방식의 상대적 장점이 Ablation Experiment에서 더욱 두드러졌다고 하네요!
📌 Conclusion
Mask R-CNN은 기존 Faster R-CNN의 RoI Pooling 방식에서 발생할 수 있는 Misalignment 문제를 RoI Align 방식으로 변경하여 공간 정보 보존 측면에서 디테일을 조금 더 살릴 수 있었고, 객체의 클래스 예측과 바운딩 박스 오프셋 계산 이외 마스크 브랜치를 하나 더 추가함으로써 Instance Segmentation 분야에서의 경쟁력을 입증한 모델이었습니다. 또한 실험 과정에서 Key Point Detection과 같은 분야로 Task를 확장함으로써 뛰어난 범용성까지 보였다는 점에서 그 의의가 있습니다.
📌 느낀점(논문을 읽으면서..)
진짜 레퍼런스 영상을 보면서 대충 개념을 넘겨짚을 때만 해도 생각보다 별게 없네? 라고 생각했었는데 이번에도 역시 저의 큰 오산이었던 것 같습니다.. 정말 깨알같은 개념이 많이 숨겨져있어서 예상한 것 보다 오랜시간 애를 먹었습니다. 그럼에도 불구하고 모델 자체는 Segmentation 범용성 측면에서 YOLO와는 또 다르게 큰 혁신이 있었던 것 같고, 단순해보이지만 브랜치 추가 아이디어를 어떻게 낼 수 있었을까를 생각해보면 정말 1류 AI 연구진 분들은 다시 한번 대단하다고 느낍니다..
📌 References
https://velog.io/@oooops/RoIPool%EA%B3%BC-RoIAlign-%EC%B0%A8%EC%9D%B4%EB%8A%94 https://velog.io/@imfromk/CV-Understanding-RoIsRegion-of-Interest#roi-align